Current Work
August 14, 2015
As part of the NEH funded Global Currents Digging into Data project, I have been working collaborators at Stanford, including Elaine Treharne, Benjamin Albritton and Celena Allen, on the visual analysis of the Parker Library‘s corpus of medieval manuscripts. With Mohamed Cheriet’s lab at ETS, we have helped to train an algorithm to recognize a set of mise-en-page features from the manuscript collection.
This not only gives us a way to identify, so far, examples of Litterae Notabiliores, enlarged capitals and rubrics automatically in a large collection of manuscripts, but also the ability to generalize the mise-en-page of the manuscripts across time and nationality. In the following images, I have scaled all of the manuscripts in our corpus (recto and verso separately) to the same size and, using the bounding box data for each of our features, I have created an overlay of all of that set of features across all manuscripts. These composite images show us, for the first time, the aggregate page layouts of these manuscripts, allowing us to easily spot large scale trends and outliers.

Composite image of all litterae notabiliores on corpus manuscripts (recto)

Composite image of all litterae notabiliores on corpus manuscripts (Verso)
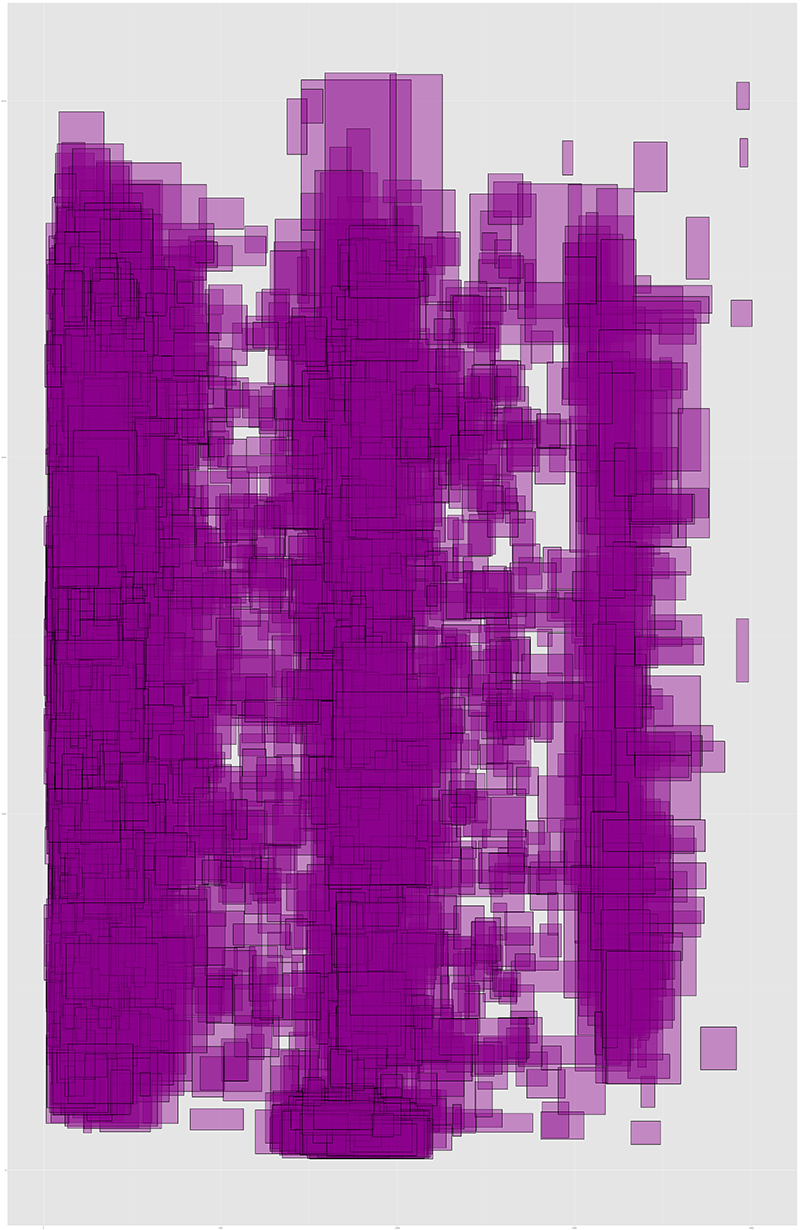
Composite image of all enlarged capitals on corpus manuscripts (recto)

Composite image of all enlarged capitals on corpus manuscripts (verso)

Composite image of all rubrics on corpus manuscripts (recto)

Composite image of all rubrics on corpus manuscripts (verso)