Discourse, Design, Disorder
How can information theory improve our understanding of Literature? As a communicative medium, Literature stands apart from other kinds of language-based information transfer. In information theory, messages (individual instances of communication) are assessed based on the amount of information transmitted, the clarity of that information, and the space and/or time required to transmit the message. Literature, however, through tropes, symbols, allegories and other poetic and literary devices, does much of its communicative work outside of the straightforward expression of meaning, using a much higher density of information per word, phrase or sentence. In this project, I return to the information theory of the mid-twentieth century, particularly the theory of information entropy described by Claude Shannon and Warren Weaver in their Mathematical Theory of Communication, in order to reassess what we can learn about literary communication by describing mathematically its use of language.
For example, although it is a truism that poetry and prose communicate differently, the underlying linguistic aspects of this difference are still relatively unexplored. An idea, or concept, or even narrative mediated through the novel will offer a radically separate experience to the reader than the same content mediated through poetry. Roman Jackobson explored this briefly in his 1960 lecture “Linguistics and Communication Theory” (and later through collaborative work with Tomaševskij), but the lack of computational power frustrated efforts to bring together information theory and the study of literature. With the current methods of the Digital Humanities, however, I am able to use Shannon’s theory to explore the functional differences in different aesthetic literary media.
Although entropy, Shannon’s primary contribution to communications theory, is routinely used in linguistics and natural language processing to assess the similarity or differences in a set of information bearing objects, in this project I treat the relative entropy of a text, or a corpus, as an informative metric in and of itself. The entropy, or its opposite, redundancy, measured in a text treated as a complete language system reveals much about both the information density of that text (how much it communicates in how many words) as well as the tendency of the text to repeat. Entropy measures the predictability of language: given a word in a text with high entropy, the next word would be difficult to predict. In a text with low entropy (and, therefore, high redundancy) the following word would be much easier to predict. Low entropy texts repeat sequences of words, rather than individual words. This metric, therefore, does not only allow me to measure a new aspect of literary writing, but it also returns meaning to the order and sequence of words in a text, something that has been largely disregarded in current quantitative text analysis.
To answer my primary question about the difference between poetry and prose I measured the entropy score for over 5000 novels from between 1700 and 1900 and the poetic corpora of 700 poets (totaling over 131,000 individual poems) over the same period. In the box plot below, blue dots represent prose novels and orange dots represent the corpora of individual poems. The y axis indicates how entropic each text is.

Box Plot of Entropy in Poetry and Novels
It is immediately apparent from this box plot that the poetry samples are significantly more entropic than the novels. The higher the entropy score, the less predictable the language is in the text and the more information contained within fewer words. Already what is clear is that the language of poetry has much more invested in surprise and the unexpected, while the language of novels has a higher tendency to repeat throughout a single text.

Entropy in Romantic Period Poetry
When I project these entropy scores across time (based on the dates of composition) we can not only see the differentiation between poetry and prose across the two centuries, but also the large scale trends in poetic and novelistic composition. While the median poem remains more entropic than the median novel, over time, the two converge: poetry becomes more like prose in its use of language, while prose discourse appears to become much more poetic throughout the nineteenth century.
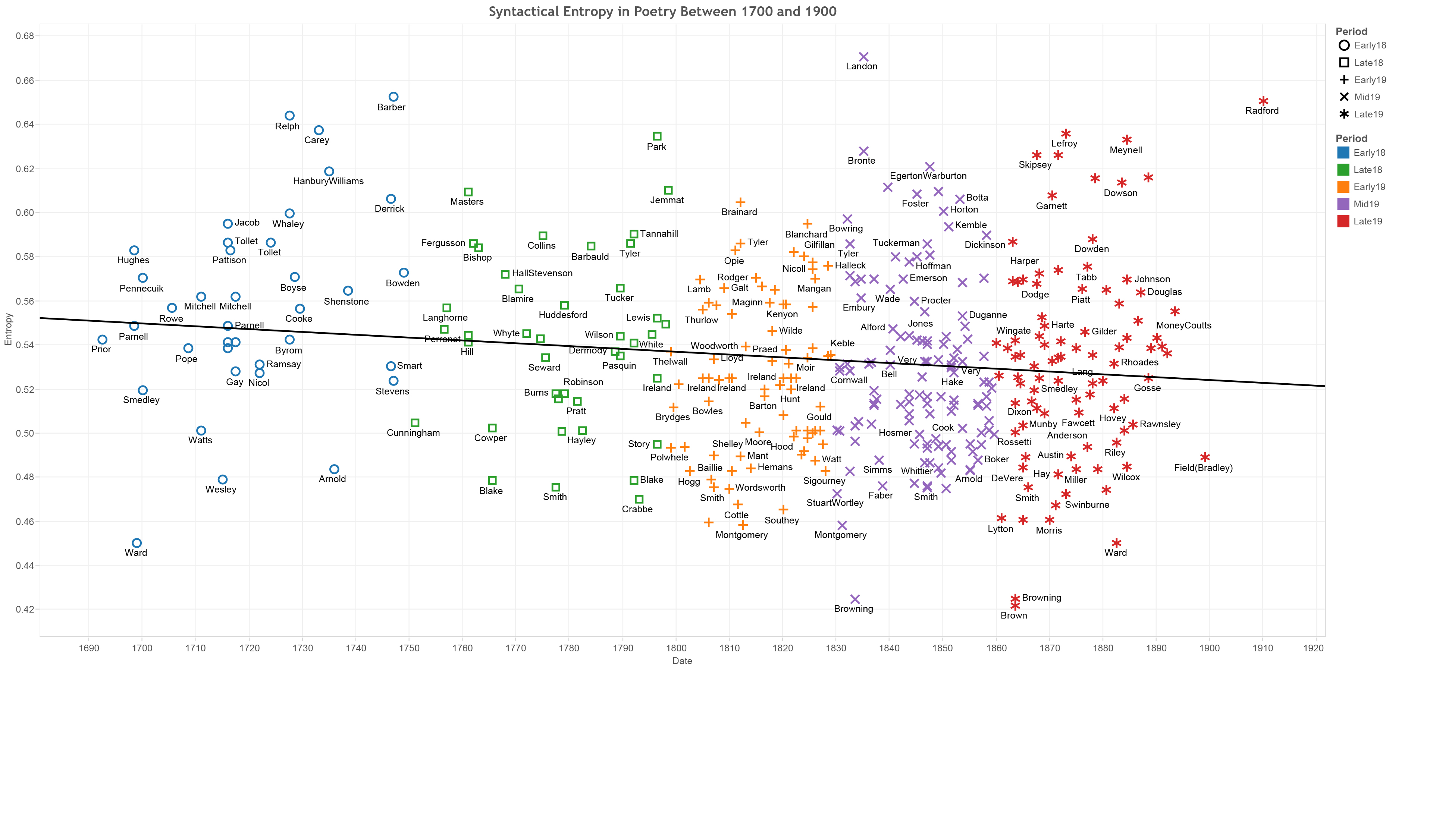
Entropy in Poetry (1670-1900)
With a graph of just the poetry, we can even see trends among the individual authors. For example, in the eighteenth century, canonical authors, such as Pope, Young or Thomson, appear to be much higher on the graph, thus much less redundant. By the Romantic period, the primarily male canonical authors are much closer to the median of their period.
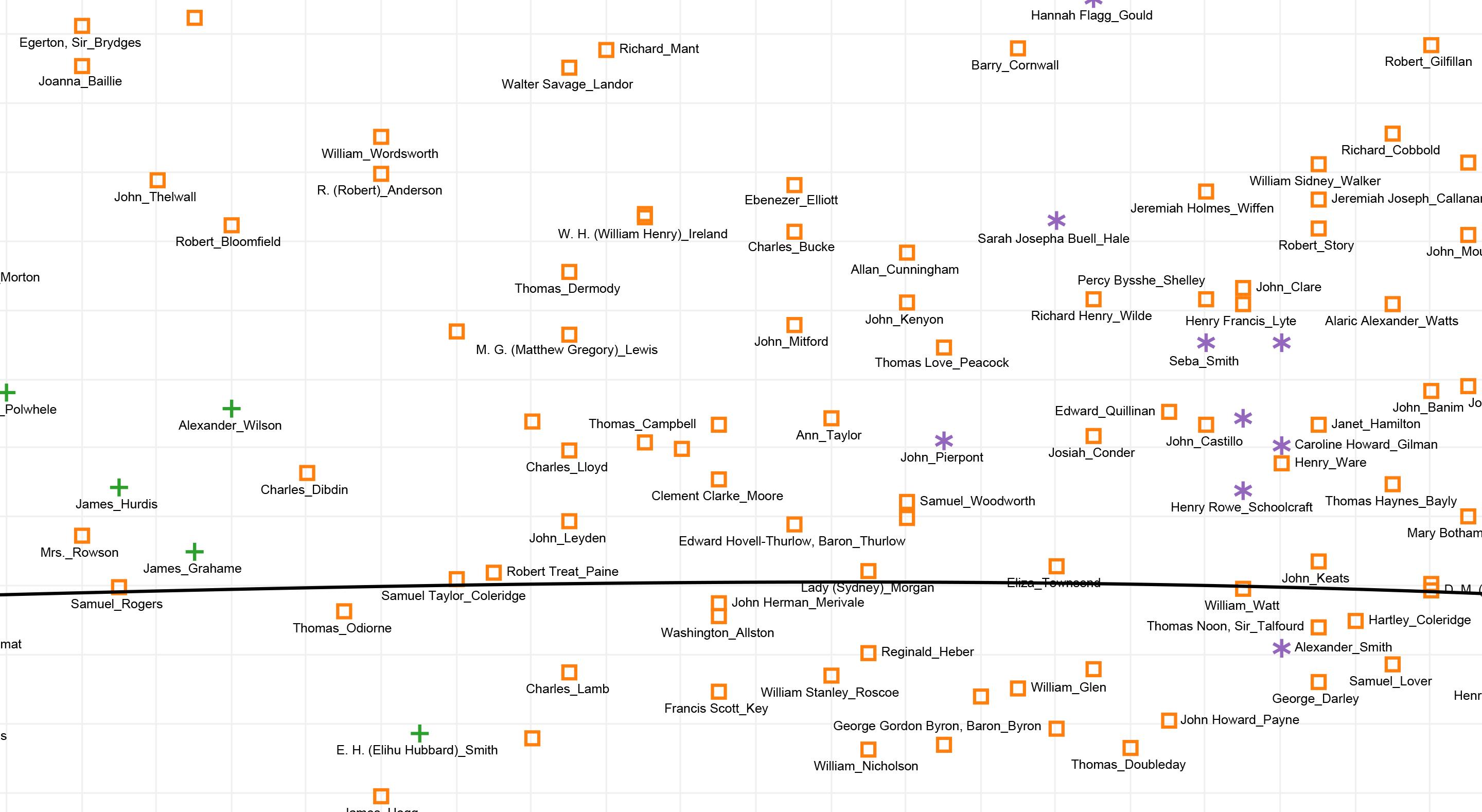
Entropy in Romantic Period Poetry
Here, Keats and Coleridge hover just at the line, while Byron and Lamb are actually more redundant than is typical for their period. Moreover, the most entropic (and thus least repetitive poetry) appears to be written by female authors of the early to mid-nineteenth century: Mary Russell Mitford, Letitia Elizabeth Landon and, above all Felicia Hemans.
This project, therefore, offers a new way to think about the literary and linguistic aspects of both individual authors and the media that they wrote in. By using communication theory to explore these differences, this project is able to offer something new to not just our understanding of eighteenth and nineteenth-century literature, but the communicative properties of Literature itself.