The Cryptic Novel
As the narrative of the “rise of the novel” has been dismantled recent criticism, it has left a void in our history of eighteenth-century literature. Were the experimental prose fiction texts of the eighteenth century merely prototypes of precursors to the novel? Or was there instead a taxonomic system already in place, a pre-history of the novel with its own internal generic consistencies and differences? This is the question that the Cryptic Novel project seeks to explore. Using the Eighteenth Century Collections Online (ECCO) corpus, we reappraise the texts that have, in our current generic system, been identified as ‘novels’ to see if we can uncover traces of previous literary identities. Early on in the project, we identified titles as the most likely source of generic identification. Our work, therefore, seeks to explore the relationship between titles and texts in this period. When an author (or publisher) in the eighteenth century titles a text as a “romance,” “history,” “tale,” or even “novel,” what work does this do both within the literary marketplace, and in the writing of the text itself? Is a “life” different from a “history” in the subject or language of the text? And, if so, how?
For this project, we selected eight title labels (history, life, adventures, letters, tale, novel, romance and story) and took a quantitative approach to explore the effectiveness of the title labels in defining discrete types of writing. If these labels were merely a publishing convention, then we should be unable to reliably tell the difference between texts marked with these different nomenclatures. If, however, these titles marked real differences between the texts themselves, then we have recovered the first evidence of a uniquely eighteenth-century generic system.
To explore this question, we turned to the methods of classification. We first derived two different sets of words from each group of text (labeled with one of our eight labels): most frequent words (MFW) and most distinctive words (MDW). We created two distinct feature sets out of these texts and subjected the resulting table to a Linear Discriminant Function Analysis to assess the success of our model in classifying texts into their correct label groupings.
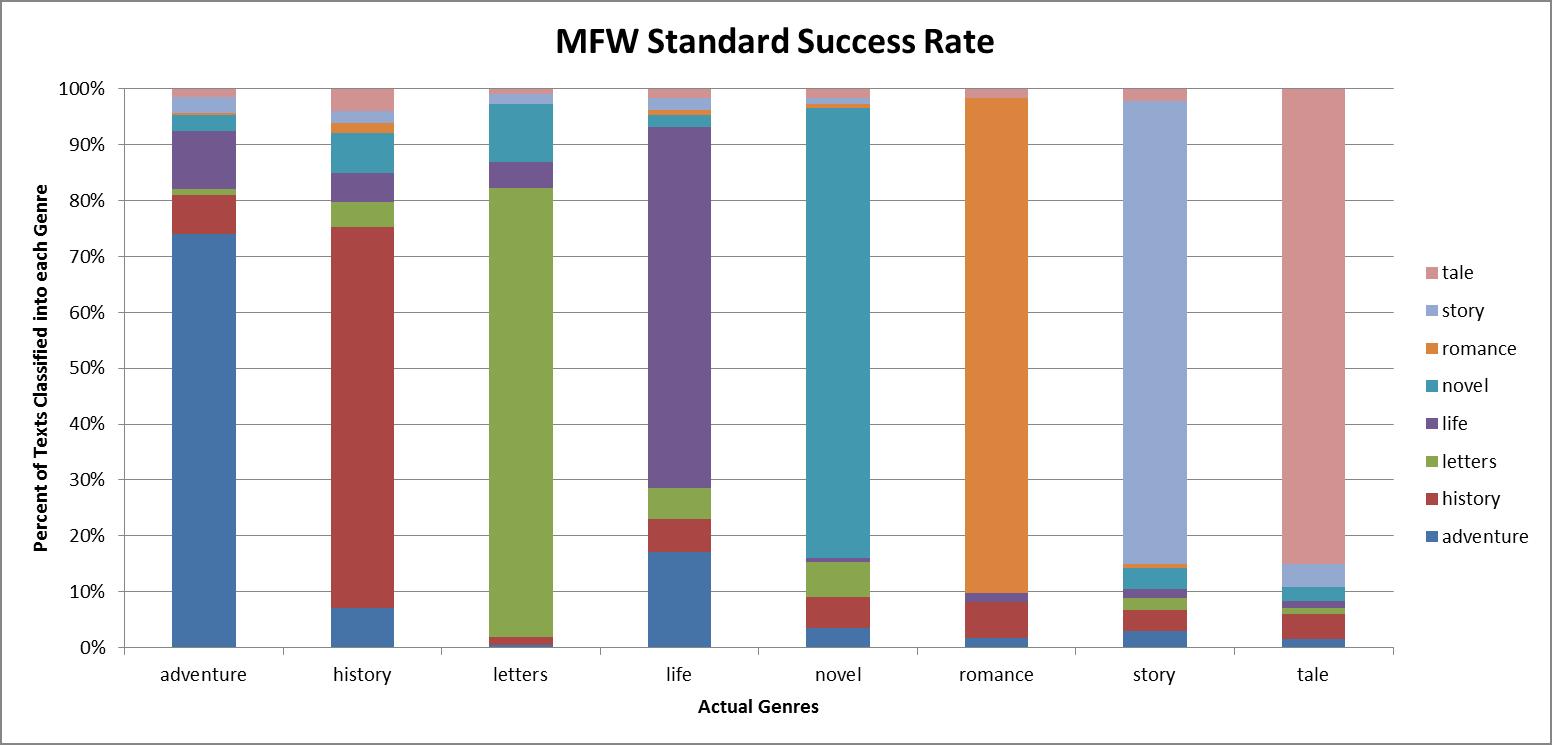
Genre Classification: MFW Standard Success Rates
In the above plot, each bar represents the total percentage of texts in each of our genre groups. The colors of the bar indicate the groups that each text in that genre group was assigned to by our classification model. Overall, we were surprised at how accurate the classifications were. Although overfit to our sample of texts from ECCO, we were able to achieve a 75% success rate based solely upon the MFW. When we turned from the MFWs to the MDWs and cross-validated our results, our success rate slipped to 48%: lower, but still much higher than the 12.5 % that would have been the result of chance.
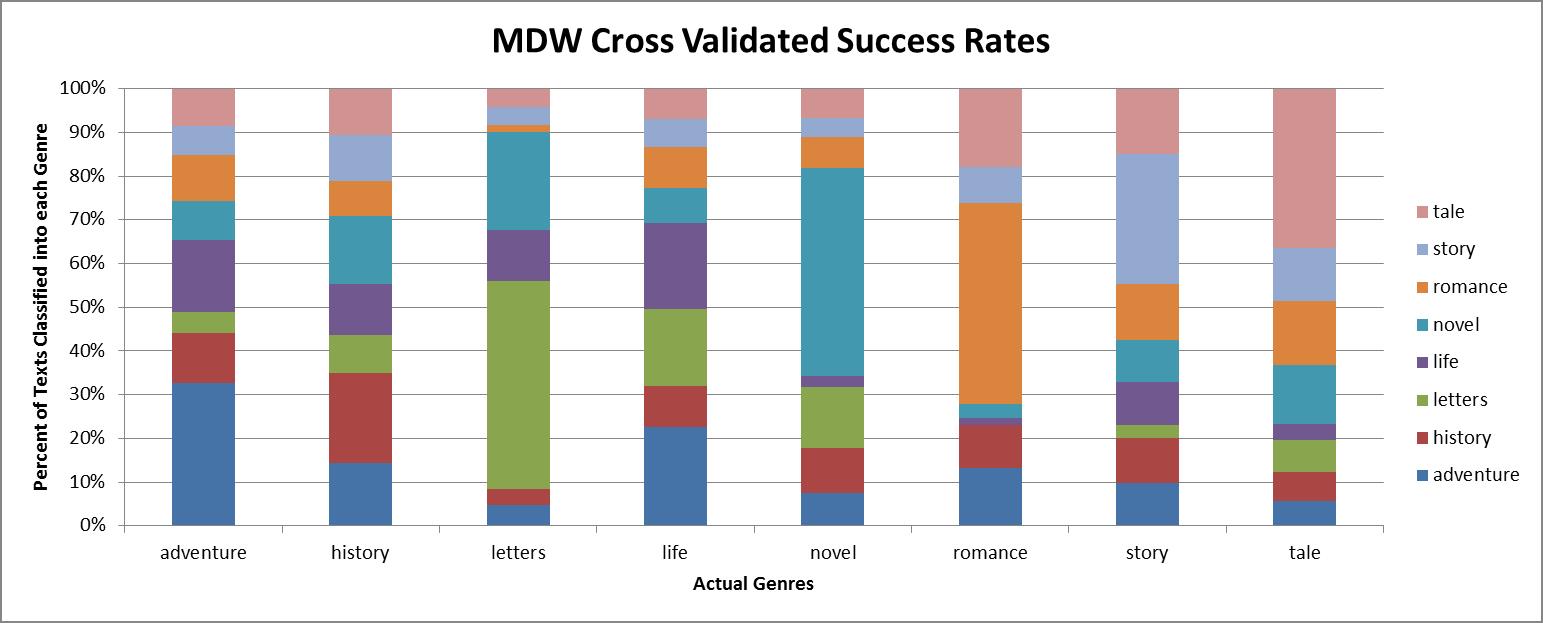
Genre Classification: MDW Cross-Validated Success Rates
It is worth noting that even these results reveal interesting aspects of the eighteenth-century textual system. In each of our groups, the greatest number of texts classified with the correct group, with the exception of “life,” which was equally likely to be classified as an adventure as a life (due, in no doubt to the prevalence of texts titled “The life and adventures of…”). It is also clear that of our groups, the strongest signals came from the three labels that were prominent during the late eighteenth century: the tale the romance and the novel.
To explore the relationship between these three groups (and, in fact, between all of the groups) we turned from a set of lexical features to a topic model and from a Linear Discriminant Function Analysis to a finite mixture model. Using a set of 100 topics as features, we plotted the relative location of each text in our corpus and used a the MCLUST package in R to derive group assignments for each cluster. The model identified 11 distinct groups, labeled in the plot below.
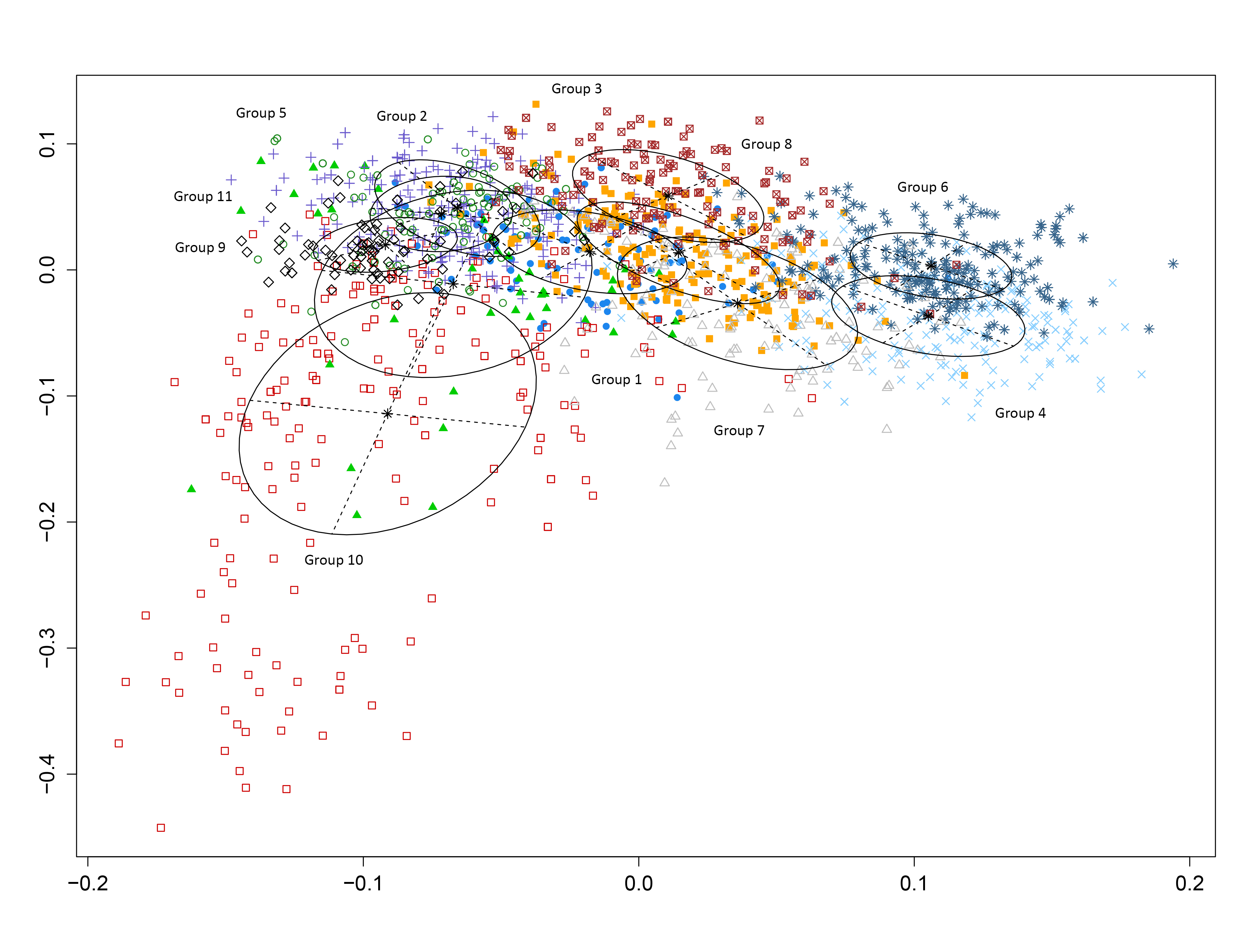
Mixture Model of Eighteenth-Century Texts
Although the 11 groups offer three more subgroupings that our data should ideally allow for, it is the position of the various genres in this text that are startling. Groups 2, 5 and 6 are predominately made up of novels. They are all tightly clustered together toward the top of the map. Conversely, group 10 is almost exclusively tales: this cluster is by far the most diffuse, despite not being the largest. From this data a surprising and significant trend emerged: novels, particularly towards the end of the century, consolidate around a few key themes and become much more topically and lexically similar. Tales, however, become much more diffuse, they are written in many different ways as they explore many different topics. It is as if, in redefining itself as the primary genre of prose fiction at the turn of the nineteenth century, the novel cast off the remainders had accompanied it throughout its eighteenth-century experimentation. The novel therefore becomes more tightly defined, while the generic capacity of the tale expands radically. Both increase in frequency throughout the century, but each does so following a different logic: consolidation vs diffusion.
Currently we are working in this project to explore this differentiation in more detail, looking beyond the eighteenth-century limits of ECCO into the future transformations of these two key genres in the early nineteenth century.