Fragments of Fiction
First presented at the MLA conference in 2014, this project uses the new methods of quantitative textual analysis to put pressure on past theories of literary criticism. In particular, Bakhtin’s theory of the novel presents an interesting challenge to the digital humanities. In his Discourses on the Novel, Bakhtin claims that novels, as compared to poetry, evidence heteroglossia: that is, as compared to the mono-vocal unity of poetry, the language of the novel is rooted in a set of competing voices and overlapping discourses. If this is true, and if we can operationalize Bakhtin’s theory of discourse, it should be possible to test Bakhtin’s theory and computationally explore the differences between the language of novels and poetry using a simple and straightforward metric.
The metric that I propose in this project is that of heterogeneity, or self-similarity. The theory behind the analysis argues that, as discourse in a novel (or poetry) is ultimately reducible to words, shifts in discourses will be accompanied by changes in the underlying lexical patterns. If individual parts of a text, therefore, are less similar to each other based on the words that each part is constructed from, then the text, by extension should evidence multiple discourses and be, by definition, more heteroglossic. A text whose individual parts are more similar would have fewer discursive shifts and be more monologic. Take, for example, the plot below: each point in the principle component analysis represents a part of the Dickens novel Bleak House and its position within the virtual PCA space indicates its similarity (based on shared word frequencies) to all of the other parts. If we measure the distance of every part to every other part in this text, we get a single metric indicating the overall self-similarity of each part of the novel to all the other parts of the novel.
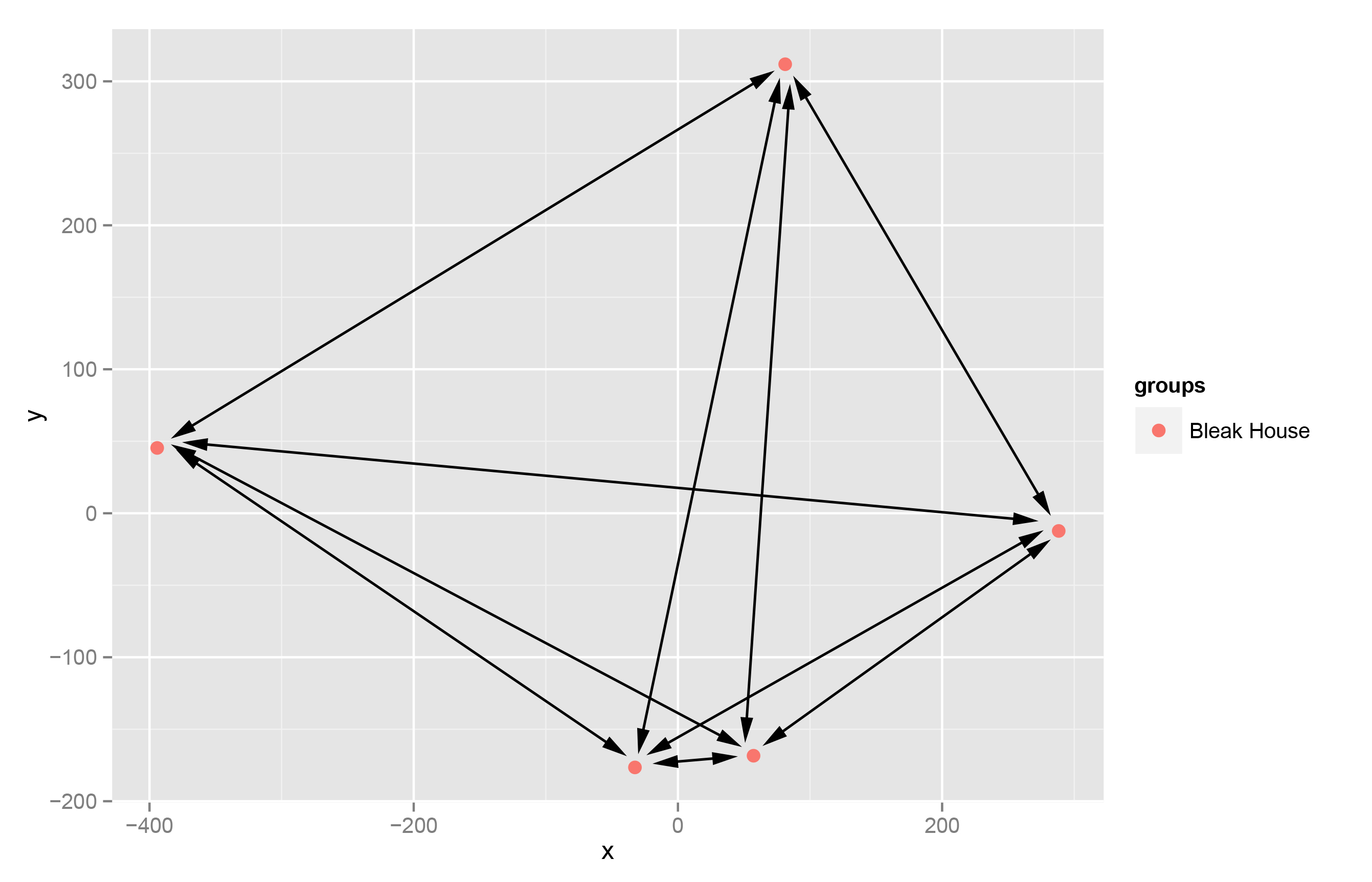
Plot of Distances in Bleak House
If we do the same for a second text, here, for example, Poe’s The Tell-tale Heart, I can again measure the same set of distances and derive the heterogeneity score for this text as well.
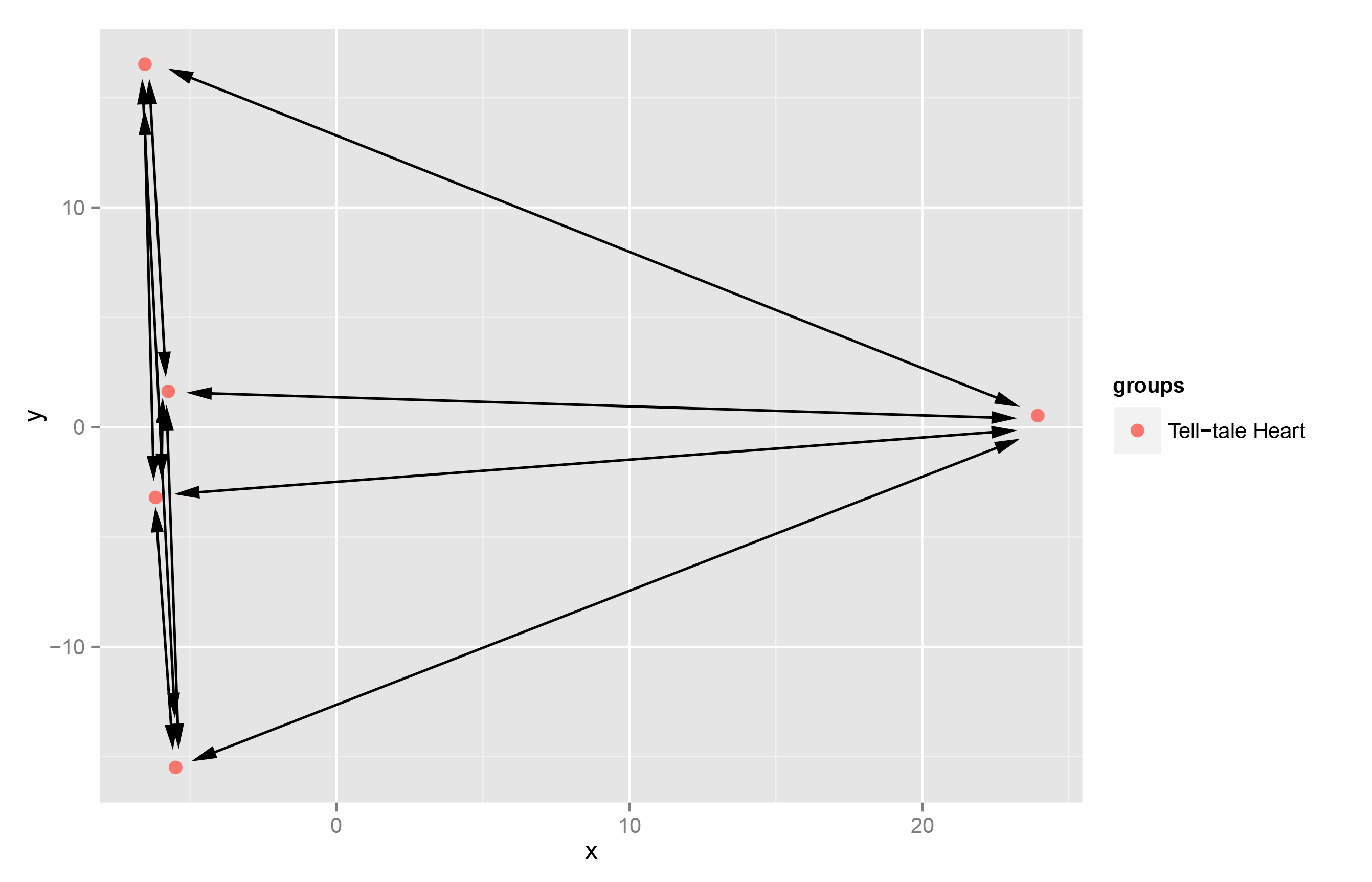
Plot of Distances in Tell-Tale Heart
By superimposing them on the same plot, it becomes apparent that the overall heterogenetiy of Bleak House is much greater than that of Poe’s short story.
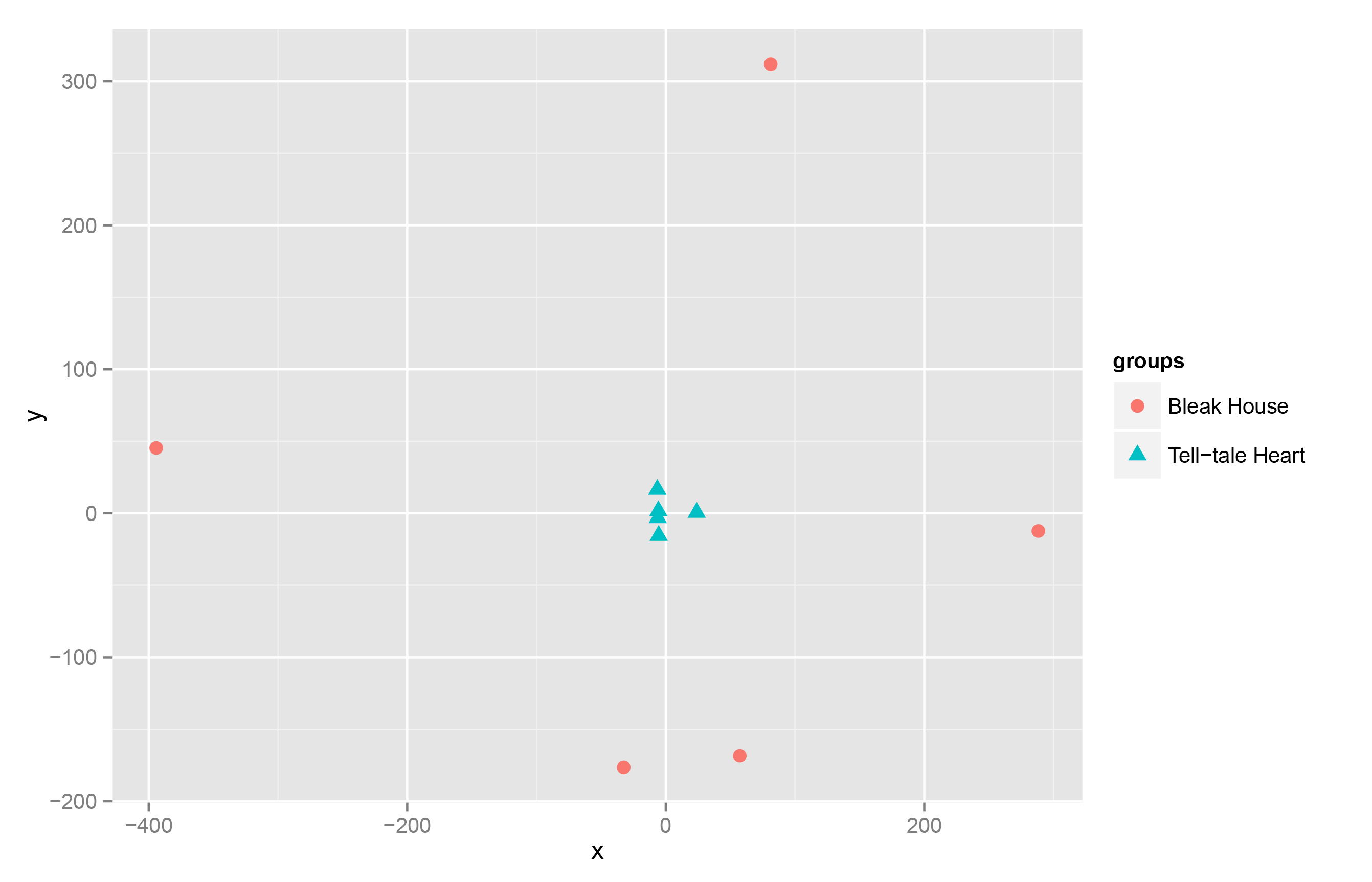
Bleak House and Tell-Tale Heart Compared
In this example, the difference is a function of the length of the text; moreover, distances between points in PCA space fails to take full account of the similarities and differences between all of the words of each part of the text.
To full explore Bakhtin’s theory of heteroglossia, this project uses a sample of 100 long poems, 100 novels and 100 works of nonfiction (all from the mid nineteenth century). Rather than measure intra-textual distances from visualizations, I divide each work into 50 equal slices and derive the similarities between each part using a Kullback-Leibler divergence (an asymmetrical measure of similarity based upon relative entropy).
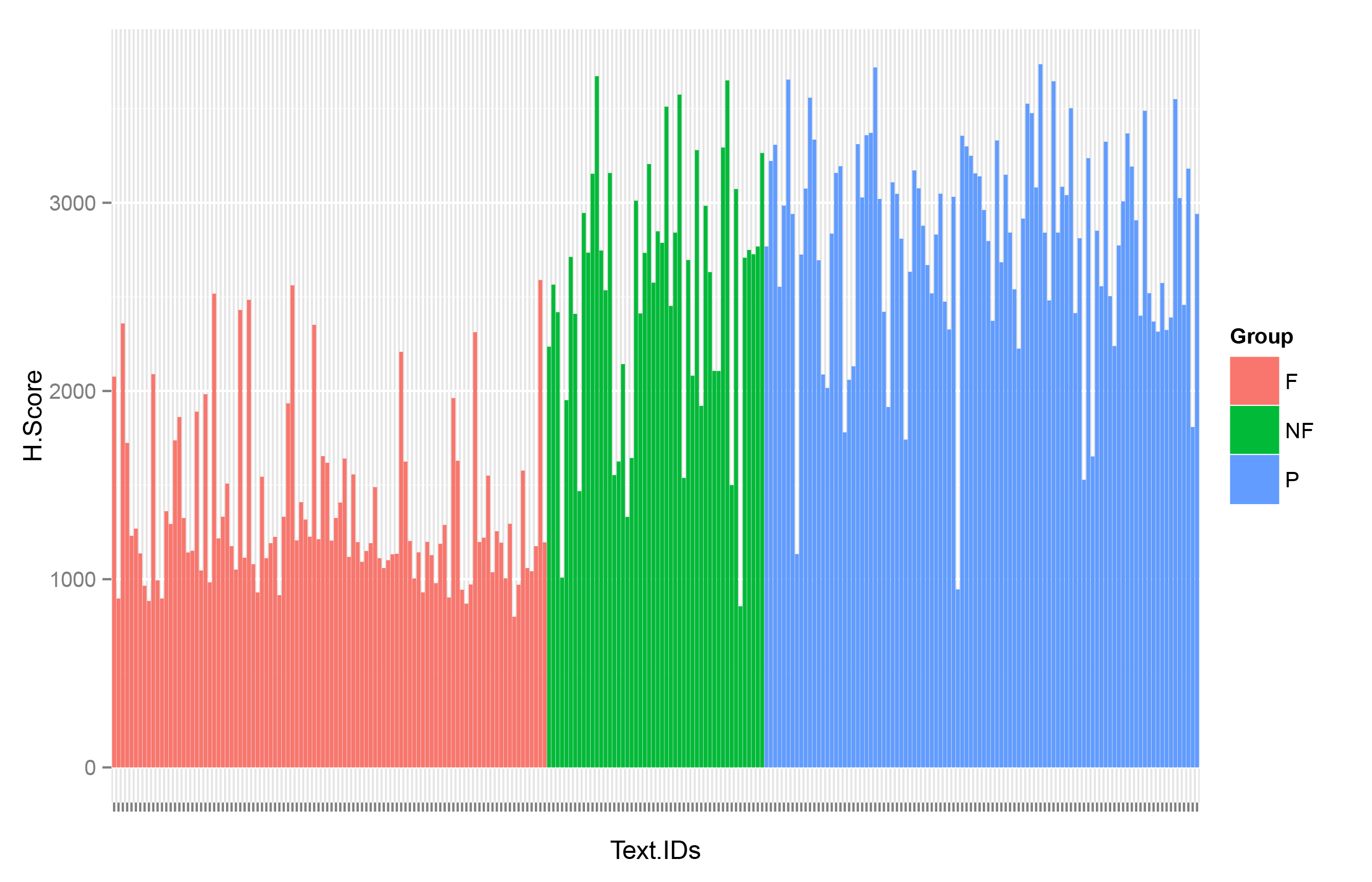
Barplot of Relative Heterogeneity
The resulting graph is striking. Overall, the novels are much less heteroglossic than the poetry, indicating that there is a much wider variety of language used in poetry, than in novels. A box plot confirms this result: overall, poetry and non-fiction is much less self-similar than novels, based on the language of their constituent parts.

Boxplot of Relative Heterogeneity
In this project, therefore, I turn from simply operationalizing Bakhtin’s theory, to exploring what this means for our understanding of heteroglossia and the relationship between poetry and prose, as well as the responsibility of computational methods to the critical theory that informs them.